

monday.com의 모든 것은 데이터로 시작되서 데이터로 끝납니다. 따라서 우리(monday.com)는 시스템의 성공적인 구동을 위해 모든 데이터를 정확하고 정밀하게 측정해야 합니다.
우리가 자체 BI 솔루션인 빅브레인(BigBrain)을 처음부터 구축한 이유는 monday.com에서 제공하는 모든 KPI를 추적하고 투명성을 제공하여 팀원 모두가 쉽게 액세스할 수 있도록 하기 위해서 입니다.
우리 빅브레인 팀(현재 4명의 엔지니어가 있으며, 추가로 채용 중)은 monday.com의 성장 가속화에 기여하면서 빅브레인 솔루션을 강화하기 위한 대규모 프로젝트를 수행했습니다. 이 사례 연구 포스팅에서는 빅브레인의 개발자인 Daniel Mittelman이 SingleStore를 사용한 이유와 방법, 그리고 왜 그 과정이 대단한지에 대해 설명합니다.
monday.com는 놀라운 속도로 성장하고 있습니다. 점점 더 많은 사람들이 웹사이트를 방문하고, 새로운 계정을 등록하고, 플랫폼을 사용해 보고 있습니다. 또한, 더 많은 고객들이 monday.com과 함께 일할 수 있도록 그들의 계획을 업그레이드 하고 있다.
앞에서 언급했듯이, SingleStore는 (당연히 개인 정보 보호 문제를 고려하면서) 사용자의 행동에 대한 데이터를 수집하고 분석합니다. 이를 통해 향후 몇 년간의 사업 계획을 수립하고 제품 개선 방법에 대한 더 나은 결정을 내릴 수 있습니다.
하지만 비용이 듭니다. 사용자의 수와 제품 내 사용 가능한 기능의 수가 증가한다는 것은 아래 차트를 보면 알 수 있듯이 매우 빠른 속도로 데이터를 적재하고 있다는 것을 의미합니다.
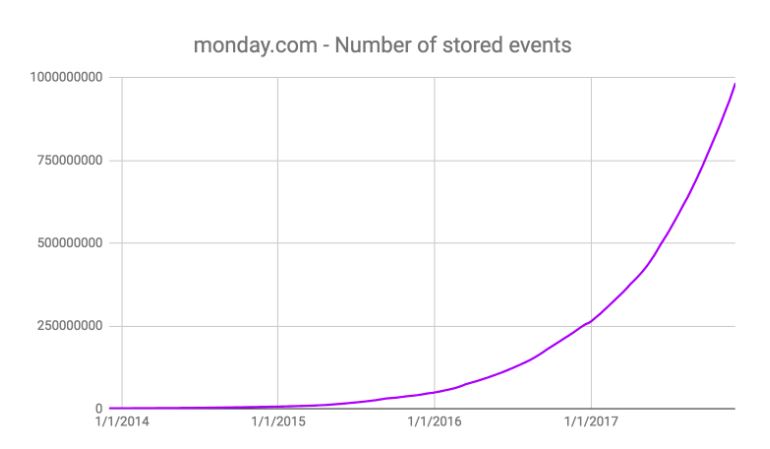
2016년 1월엔 약 5천만 개의 계약 데이터가 있었으며, 1년 뒤인 2017년 1월에는 2억 6,500만 개로 늘었습니다. 우리는 10억개가 넘는 데이터를 가지고 2018년 크라우드 펀딩을 받기 시작했습니다.
이 데이터는 빅 데이터 분야에서 볼 땐 큰 양이 아니지만, 간단하게 계산해보았을 때 2019년까지 데이터풀에 40억 개의 데이터가 저장될 것이라는 것을 알 수 있으며, 2020년에는 150억 개의 데이터를 저장할 수 있을 것이라고 예측할 수 있습니다.
이러한 예측을 바탕으로 우리는 기존에 사용하고 있던 Elastic Search가 1년 이내에 한계에 도달할 것이라 생각했습니다. 물론 Elastic Search는 토큰 기반 검색에 적합한 데이터베이스로, 기본 데이터 분석 작업(주로 카운트 및 버킷 작업)이 주어졌을 때도 성능이 매우 우수합니다. 그러나 Elastic search는 여러 인덱스에 대해 집계를 수행하고 이를 조인(Join)하거나 복잡한 조건 검색(필터링)을 수행하는 등 더 큰 문제를 해결할 능력이 부족합니다. monday.com에서 사용자 참여에 대한 보다 확실한 결과를 확인할 수 있는 이러한 복잡한 분석이 필요한 것은 당연합니다.
우리는 2017년 중반부터 새로운 분석 데이터베이스를 찾기 시작했습니다. Amazon의 Redshift, Google의 BigQuery, Microsoft의 Cosmos DB와 같은 클라우드 기반 데이터 웨어하우스부터 MapD, Kinetica와 같은 새로운 GPU 기반 데이터베이스 분야까지 가능한 모든 데이터베이스를 살펴보았습니다. JSON 형식의 S3 버킷이 지원되는 Amazon의 Athena도 확인했습니다.
각 데이터베이스마다 장단점이 있었습니다. 데이터베이스마다 옵션이 다양하여, 솔루션에 대한 우리의 정확한 요구 사항을 선정했습니다. 아래의 요구 사항 리스트는 중요도순으로 작성했습니다.
- 속도: 요청은 대부분의 경우 6초 이내 처리되어야 하며, 최대 30초를 초과하면 안됨
- 다기능성: 단일 계산 중에 서로 다른 데이터 유형끼리 Join 가능
- 분산: 복제 및 내결함성을 통해 고가용성 제공
- 보안: 데이터 미사용 또는 전달 중에 암호화에 대한 요구 사항 충족
- Ruby on Rails와 연계 가능: 백엔드 개발을 위해 사용하는 프레임워크인 Ruby on Rails 연계 가능
- 쉬운 확장성: 데이터베이스의 확장이 용이
- SQL: SQL 사용 가능
- 합리적인 비용: Elastic Search 클러스터의 9개의 노드 사용 비용(월 3,600달러) 이내
속도와 다기능성은 당사의 가장 중요한 요구사항이었으며, 해당 요구사항은 갖춰지지 않을 경우 대부분의 클라우드 기반 솔루션이 실패하는 원인이 되기도 합니다. Redshift와 BigQuery에서 복잡한 쿼리 중 일부를 테스트하였으나, 50초에서 몇 분에 이르는 실망스러운 실행 시간 확인하였습니다. Cosmos DB는 실제로 인상적인 벤치마크 결과를 보여주었지만, 공식적으로 Ruby 지원을 하지 않고 있습니다. MapD와 Kinetica도 마찬가지입니다.
마지막 도전 업체는 SingleStore라는 메모리 기반의 데이터베이스 솔루션이었습니다. SingleStore의 Enterprise Edition은 다기능성과 SQL에 대한 지원을 포함한 모든 요구사항을 충족하는 것처럼 보였습니다. 하지만 SingleStore가 속도에대한 요구 조건을 충족시킬 수 있을지에 대한 문제는 여전히 알 수 없었습니다.
SingleStore의 웹사이트는 많은 전통적인 데이터베이스 엔진보다 뛰어난 데이터베이스 속도에대해 소개하고 있지만 그 소개자료 때문에 데이터베이스를 테스트하는 것을 생략할 수 는 없었습니다. 물론 지금까지 이 게시물을 읽어보았다면 알 수 있듯이, 결과는 훌륭했으며, 이제 기술적인 측면에 대해 더 자세히 알아보겠습니다.
다음은 빅브레인 내의 SingleStore를 중요한 분석(시간 경과에 따른 집계를 보여주는 차트 이외의 모든 분석)에 사용하는 방법에 대한 몇 가지 실제 사례입니다.
1. End-to-End 마케팅 성과
AdWords Account Manager나 Facebook Ad Manager와 같이 많은 마케팅툴은 광고(캠페인)의 비용을 표시함으로써 광고가 어떻게 수행되는지, 그리고 해당 광고가 얼마나 많이 노출되고, 클릭 되었는지에 대한 자세한 정보를 제공합니다.
우리는 마케팅 출처, 광고, 심지어 단일 배너에 대한 분석까지 수행하기 위해 몇 단계 더 나아갔습니다. 각 배너와 관련된 광고가 웹사이트로 불러온 방문자의 수, 가입한 사람의 수, 그리고 결국 유료 고객이 된 사람의 수 등을 표시합니다.
이를 통해 고객 유치 비용(CAC), 투자 수익률(ROI)과 같은 부문별 KPI를 계산할 수 있습니다. 이러한 종류의 계산에는 6개의 테이블, 때로는 수천만 개가 넘는 레코드가 필요합니다. 이 레코드는 8코어 서버의 Postgre에서 1분 이내에 완료할 수 없습니다. 그러나 SingleStore에서는 몇 초 만에 요청에 대한 결과를 반환합니다.
2. 필터링
필터링 툴을 사용하여 이벤트 기반 프로세스(1800개의 다양한 방문 유형 중)를 구성하여 주어진 시간 내에 프로세스를 통과하는 방문자, 사용자 및 계정 수를 확인할 수 있습니다.
더 중요한 것은 사용자 환경이 최적 상태가 아닌 원인을 파악하여 플랫폼에서 미세한 조정을 할 수 있다는 점으로 일종의 monday.com의 전용 UX 디버깅 도구라고 생각하시면 됩니다. 또한 A/B 테스트 실행 시 조건을 세분화하여 테스트별로 제공되는 사용자의 동작을 분석할 수 있습니다. 우리는 "조인(Join)과 리듀스(Reduce)" 과정을 반복하여 필터를 제작합니다. 따라서 필터의 각 단계에서 특수 제약 조건이 있는 서로 다른 외부 조인(OUTER JOIN)을 [체결] 스토리지에 요구합니다. 아래는 [등록] 프로세스 필터의 예입니다.
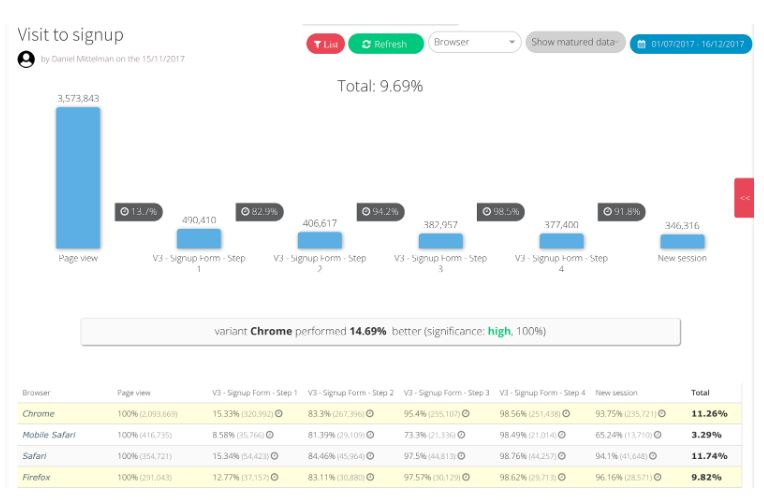
2017년 하반기 등록 프로세스의 통계치는 360만 명의 고유 방문자를 시작으로 브라우저별로 세분화되어 있습니다. 흥미롭게도, Chrome 웹사이트를 방문하는 사람들은 Firefox 웹사이트 방문자보다 실제로 monday.com의 평가판 솔루션에 가입할 확률이 통계적으로 훨씬 높았습니다. 이 필터링 분석은 단 18초 안에 계산되었습니다.
다음 포스팅에서는 SingleStore에 데이터를 저장하는 방법, SingleStore의 여러 부분이 작동하는 방법, 쿼리를 최대한 빨리 실행하도록 조정한 방법에 대해 자세히 알아보겠습니다. 또한 필터링에 지정된 순서대로 이벤트가 발생하지 않는 몇몇 필터를 포함하여 모든 필터를 계산할 수 있도록 필터링 시스템을 구축한 방법도 보여 드리겠습니다. (온라인에서 볼 수 있는 대부분의 튜토리얼에 나와 있는 것처럼 쉽지만은 않습니다.) SingleStore 클러스터를 처음부터 시작하는 프로세스와 운영에서 중요한 인프라로 설정하는 방법에 대해 살펴보겠습니다.
이 블로그의 원본 게시물은 여기에서 확인할 수 있습니다.
January 18th, 2019
출처: https://www.singlestore.com/blog/case-study-mondaydotcom-bi/
Case Study: monday.com – How our engineers supercharged our BI capabilities: A trilogy
The monday.com engineering team wrote about thier experience with SingleStore, this is a repost of that blog. To learn more, read the blog.
www.singlestore.com
※ www.a-platform.biz | info@a-platform.biz
'SingleStoreDB > 사례연구' 카테고리의 다른 글
| [사례 연구, 금융] 머신러닝기반 실시간 이상거래 탐지(미국 메이저 은행) (0) | 2021.08.10 |
|---|---|
| [사례 연구, 금융] SingleStore와 Kafka를 통한 위험 관리 성능 개선 (0) | 2021.08.10 |
| ML 플랫폼 "MindsDB"에서 SingleStore 데이터베이스를 통한 실시간 머신 러닝 (0) | 2021.06.29 |
| [사례 연구, Teespring] 실시간 분석을 통해 전자상거래 플랫폼 개선 (0) | 2021.01.12 |
| [사례 연구, Thorn] 더 빠른 인신매매 아동 식별을 위해 SingleStore Managed Service(Helios)로 데이터 구축 (0) | 2020.05.26 |



