

기록 시스템(System of Record; SoR)은 트랜잭션 데이터베이스의 성배입니다. 회사는 빠르고 효율적인 복원 기능으로 트랜잭션이 완료되고 완료된 트랜잭션을 백업하는 여러 가지 방법이 있는 신뢰할 수 있는 데이터베이스에서 워크로드(Workload)를 실행해야 합니다. SingleStore DB 7.0에는 매우 빠른 동기식 복제를 제공하는 새로운 기능이 포함되어 있어 유연성과 신뢰성이 향상됩니다. 이러한 기능을 통해 SingleStore DB 7.0은 기록 시스템이 필요한 Tier 1 워크로드에 대한 대안을 제공합니다. SingleStore Universal Storage와 트랜잭션과 분석을 동일한 데이터베이스 소프트웨어에서 결합할 수 있는 SingleStore의 기존의 기능과 결합 시 SingleStore DB 7.0은 이제 광범위한 워크로드에 대해 전례 없는 설계, 운영 단순성, 비용 절감과 성능을 제공합니다.
기록 시스템의 중요성
트랜잭션 워크로드를 처리하는 기능은 데이터베이스의 중요한 특성입니다. 데이터베이스가 기록 시스템 역할을 할 때 사용자에게 받은 트랜잭션을 잃어버리지 않아야 합니다.
기록 시스템을 제공함에 있어, 거래 속도와 시스템이 데이터 손실에 대해 제공하는 안정성의 정도 사이에는 항상 어느 정도의 절충점이 존재합니다. SingleStore DB 7.0에서는 두 가지 새로운 기능(빠른 동기식 복제, 증분 백업)을 통해 기록 시스템을 향상시킵니다.
동기식 복제는 트랜잭션이 마스터라고 하는 1차 스토리지와 슬레이브라고 하는 복제본에 쓰여질 때까지 트랜잭션이 완료(Commit)되지 않는 것입니다. SingleStore DB 7.0에서는 성능에 거의 영향을 미치지 않으면서 동기식 복제를 사용할 수 있습니다.
커밋 전에 디스크에 트랜잭션을 반영해야 하는 동기식 내구성(Durability)은 추가적으로 데이터를 안전하게 하는 도구입니다. 시간이 걸리지만 마스터에서 디스크에 쓰는 것은 슬레이브로 트랜잭션을 보내는 것과 동시에 발생합니다. 트랜잭션이 두 번째 시스템의 디스크에 기록되는 동안 추가 대기가 있습니다. 물론 성능 저하는 비동기식 복제보다 더 큽니다.
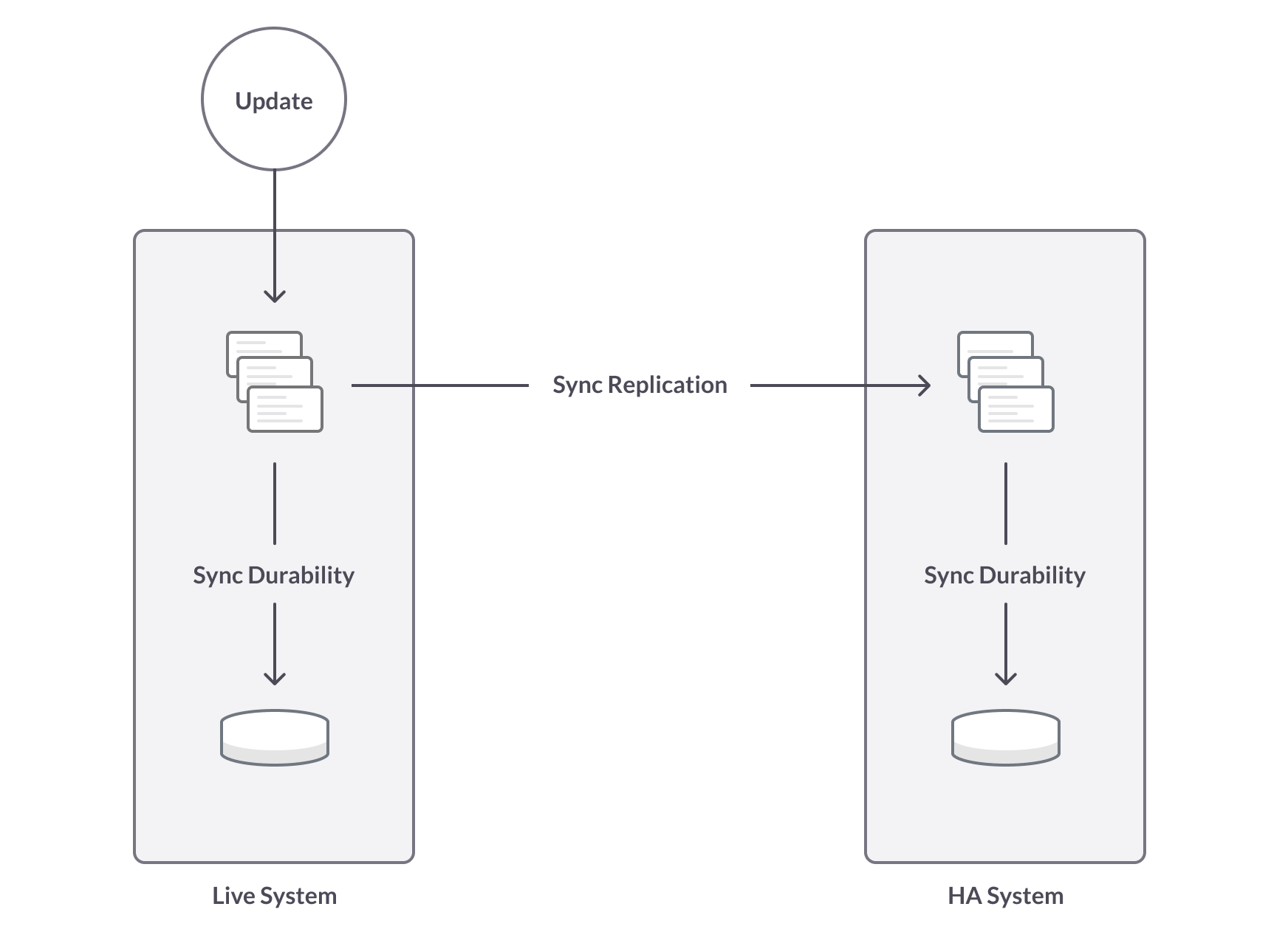
SingleStore DB 7.0의 빠른 동기식 복제를 통해 적은 성능저하로도 고 가용성을 실행할 수 있습니다.
동기식 복제 및 동기식 내구성 외에도 기록 시스템 데이터베이스에는 유연한 복원 옵션이 필요합니다. SingleStore DB 7.0에서는 증분 백업을 추가하여 백업 유연성을 크게 향상시킵니다. 증분 백업을 사용하면 시스템에 대한 추가 영향 없이 훨씬 더 자주 백업을 실행할 수 있습니다. 증분 백업은 마지막 백업 이후 변경된 데이터만 저장해야 함을 의미합니다. 따라서 백업을 수행하는 데 걸리는 시간 및 리소스가 크게 줄어듭니다. 이는 RPO(Recovery Point Objective)가 짧다는 것을 의미하며, 이는 백업 복원이 필요한 오류 발생 시 데이터 손실이 적다는 것을 의미합니다.
이 블로그 게시물의 나머지 부분에서는 SingleStore DB 7.0의 혁신적인 기능인 동기식 복제에 중점을 둡니다.
동기식 복제의 동작
7.0 이전 릴리스의 동기식 복제는 매우 신중하고 느렸습니다. 커밋되는 대로 데이터가 복제되었습니다. 따라서 작은 커밋이 많으면 적은 양의 데이터로 데이터 네트워크에 많은 별도의 트랜잭션을 보내는 오버헤드 비용을 지불하게 됩니다. 또한 슬레이브 파티션으로 전송된 데이터는 해당 시스템의 메모리에 재생된 다음, 슬레이브가 마스터에게 확인한 후, 마지막으로 사용자에게 결과를 보냅니다. 이는 많은 쓰기 작업을 수행한 워크로드의 처리량을 제한할 만큼 느렸습니다.
SingleStore DB 7.0에서는 복제 작동 방식을 완전히 개선했습니다. 커밋은 이제 네트워크에서 데이터를 전송하는 비용을 줄이기 위해 그룹화됩니다. SingleStore의 Skiplist 사용과 마찬가지로 복제도 잠금 없이 수행됩니다. 마지막으로 마스터는 슬레이브가 변경 사항을 재생할 때까지 기다릴 필요가 없습니다. 슬레이브가 데이터를 수신하자마자 승인이 마스터에게 다시 전송되고, 마스터는 승인을 사용자에게 다시 보냅니다.
SingleStore는 분산 데이터베이스이기 때문에 데이터의 여러 복제본을 유지한 다음 시스템 오류가 감지되면 다른 복제본으로 장애 조치(failover)함으로써 고가용성 시스템을 구현할 수 있습니다. 다음 단계는 네트워크 파티션, 노드 재부팅, 메모리 부족 노드 또는 디스크 공간 부족 노드의 단일 장애로 인해 데이터가 손실되지 않는 이유를 보여줍니다. 다음 섹션에서는 이러한 내결함성 구현이 어떻게 빠른지 설명합니다.
내결함성을 제공하려면 다음 단계를 따르면 됩니다.
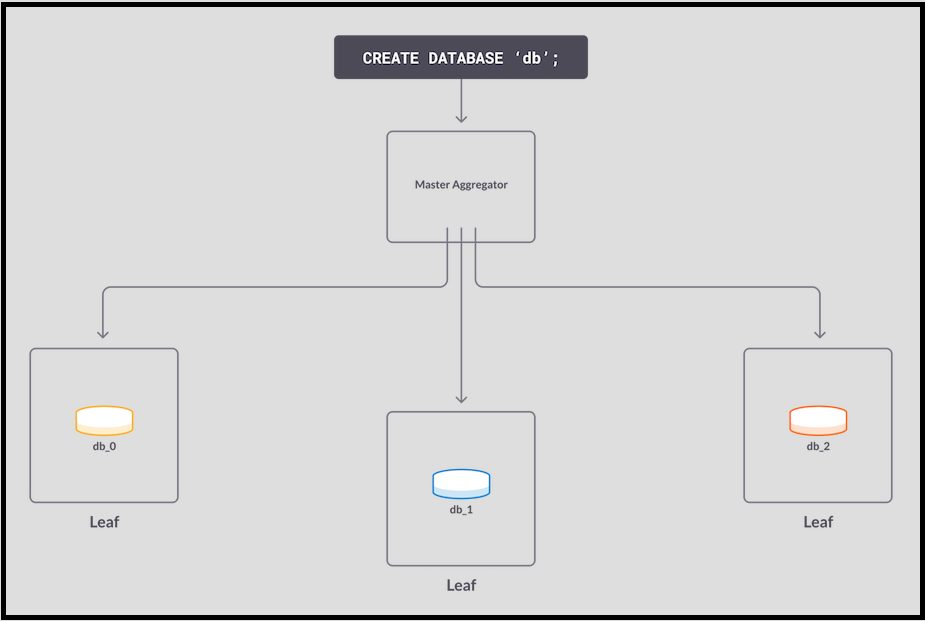
1. CREATE DATABASE 명령이 수신되었습니다. 이 명령은 동기식 복제 및 비동기 내구성을 지정합니다. SingleStore는 세 개의 리프에 파티션 db_0, db_1 , db_2를 호출하여 파티션을 만듭니다. (실제 SingleStore 데이터베이스에는 리프 당 많은 파티션이 있을 수 있지만 이 예에서는 리프 당 하나의 파티션만 있는 것으로 합니다.)
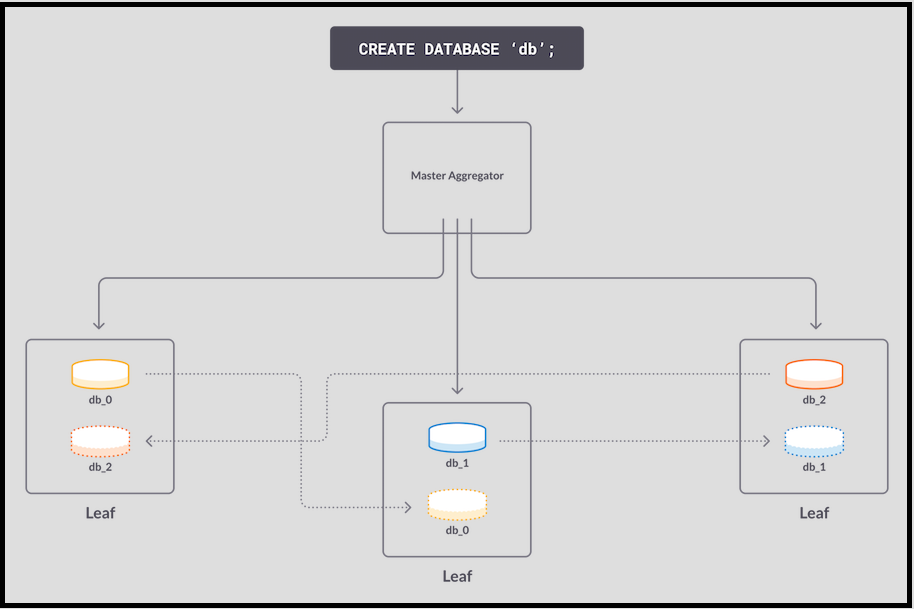
2. 이중화 2레벨(redundancy 2; 즉, 고가용성(HA), 모든 데이터의 마스터 및 슬레이브 복제본이 존재)에 의해 파티션이 각각 다른 리프에 복제됩니다. 복제가 시작되면, 마스터 파티션의 모든 변경 사항이 슬레이브 파티션으로 전송됩니다.
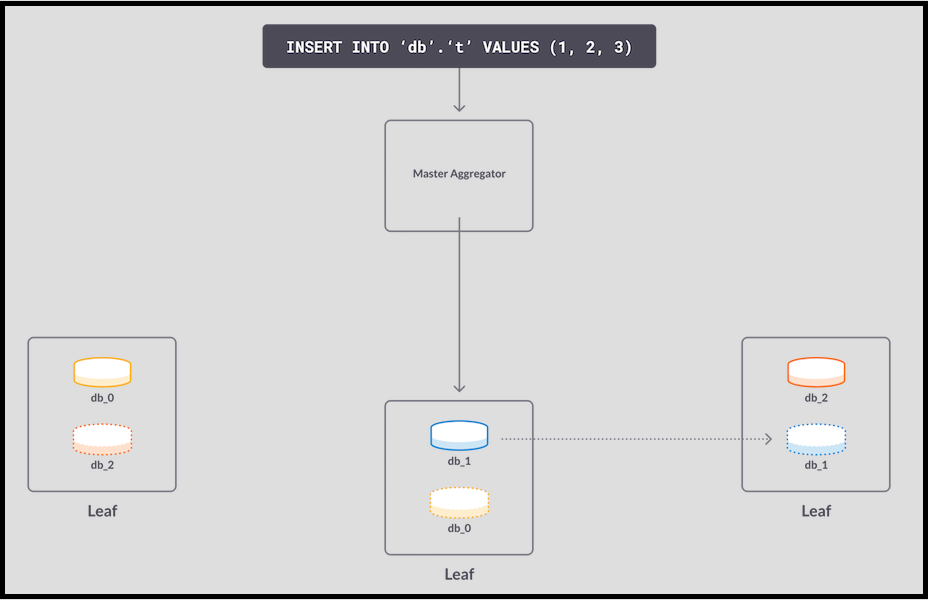
3. 삽입(Insert)이 db_1에 도달했습니다. 업데이트는 마스터의 메모리에 기록된 다음, 슬레이브의 메모리에 복제됩니다.
4. 슬레이브는 페이지를 받아서 마스터에게 승인합니다. 마스터 데이터베이스는 마스터 어그리 게이터에 대한 쓰기를 승인하고 최종적으로 이를 사용자에게 승인합니다. 쓰기는 커밋된 것으로 간주됩니다.
마스터 파티션과 슬레이브 간의 상호 작용으로 트랜잭션이 실패하지 않습니다. 두 시스템 중 하나라도 실패하더라도 시스템에는 여전히 최신 데이터 복제본이 있습니다. 슬레이브 시스템에서 로그 응답의 비동기적 특성으로 인해 빠릅니다. 기본 시스템에 대한 승인은 로그 페이지가 수신된 후 슬레이브에서 재생되기 전에 발생합니다.
로그 페이지 할당 분산 및 잠금 해제
이 빠른 성능에는 여전히 위험이 있습니다. 트랜잭션 수가 많더라도 트랜잭션이 상대적으로 작으면 전체 리프에 원활하게 분산될 수 있으며 빠른 성능이 유지됩니다. 그러나 가끔 큰 트랜잭션(예 : 큰 데이터 블록 로드)을 사용하면 큰 작업이 완료될 때까지 작은 트랜잭션이 발생하지 않을 수 있습니다.
실제 데이터 업데이트를 분산처리 할수 있으므로 병목 현상이 발생하지 않습니다. 병목 현상은 로그 페이지 할당시 발생합니다. 그래서, SingleStore는 동기식 복제 속도를 높이기 위해 로그 예약과 복제를 잠금 없이(lock-free) 수행하여 블로킹(blocking)을 줄였습니다. 새 동기식 복제를 수행하는 데 있어 가장 큰 어려움은 로그 페이지를 분산하는 것과 잠금 없이 할당하는 것이었습니다. 잠금을 방지하기 위해 함께 작동하는 몇 가지가 있습니다.
가장 먼저 이해해야 할 것은 복제 로그입니다. 복제 로그와 상호 작용하는 트랜잭션은 다음과 같습니다 : 예약, 로그 작성, 커밋.
복제 로그는 4KB 페이지들의 배열로 구성되며 각 페이지에는 여러 트랜잭션(트랜잭션이 작은 경우), 서로 다른 트랜잭션의 일부 또는 한 트랜잭션의 일부(트랜잭션 크기가> 4KB인 경우)가 포함될 수 있습니다. 각 4KB 페이지는 그룹 커밋 단위로 사용되어 개별 트랜잭션이 아닌 전체 페이지가 전송되어 네트워크 트래픽을 줄이고 가변 크기의 개별 트랜잭션이 아닌 표준 크기 페이지에서 작동하므로 필요한 코드를 단순화합니다.
페이지를 관리하기 위해 각 페이지는 첫 페이지 번호가 0으로 시작하는 고유 ID인 LSN (Log Sequence Number)으로 식별된 다음, 각 후속 페이지에서 하나씩 증가합니다. 각 페이지에는 48바이트 스트럭처의 페이지 헤더가 있습니다. 헤더에는 두 페이지의 LSN, 즉 페이지 자신의 LSN과 커밋된 LSN (문제의 페이지가 생성될 때 모든 페이지가 성공적으로 커밋 된 LSN)이 포함됩니다. 따라서, 페이지에 LSN 번호 53과, 이 페이지가 작성된 시점에 커밋된 LSN번호 48을 기록할 수 있습니다. 처음 48개 페이지 모두가 커밋 되었지만 페이지 49 (아마도 다른 높은 번호의 페이지 등)는 아직 커밋되지 않은 것입니다.
트랜잭션이 수행중인 작업을 로그에 기록하려는 경우 로그에 논리 공간을 제공하고 실패하지 않도록 보장할 수 있는 충분한 물리적 자원을 제공하는 API가 있어 노드 자체 충돌을 방지합니다. 다음으로 트랜잭션은 로그 내에서 원하는 모든 데이터를 로그에 기록합니다. 마지막으로 커밋 API를 호출합니다. 기본적으로 데이터가 슬레이브 시스템이나 디스크 또는 둘 다로 전달될 준비가 되었음을 로그에 표시합니다.
이러한 배경을 통해 로그가 내부에서 어떻게 작동하는지 확인할 수 있습니다. 로그에 앵커라고하는 128비트 스트럭처가 있으며, 로그 예약을 위한 잠금 없는 프로토콜을 구현하기 위해 사용합니다. 앵커는 두 개의 64비트 숫자로 구성됩니다. 하나는 로그에 있는 현재 페이지의 LSN이고, 다른 하나는 다음 데이터 페이로드를 쓸 수 있는 페이지의 포인터입니다.
또한 모든 스레드는 비교-교환(CAS; Compare-And-Swap) 명령을 사용하여 앵커에서 작동하며, CPU 프리미티브는 메모리의 특정 위치가 변경되지 않았는지 확인한 다음, 하나의 스트럭처를 원자적으로 변경할 수 있습니다. 잠시 후에 볼 수 있듯이 잠금 없는 작업에 매우 유용합니다.
SingleStore DB 7.0 동기식 복제 데모
다음 다이어그램은 스레드 4개가 있을때의 앵커의 현재 상태를 보여줍니다. 그리고 간단히 하기 위해 앵커의 두 번째 부분은 표시하지 않고 LSN만 표시합니다.
1. 모든 비교 및 스왑에서 로그에 쓰려고 하는 스레드는 값이 1000인 최신 LSN을 로드하여 시작합니다.
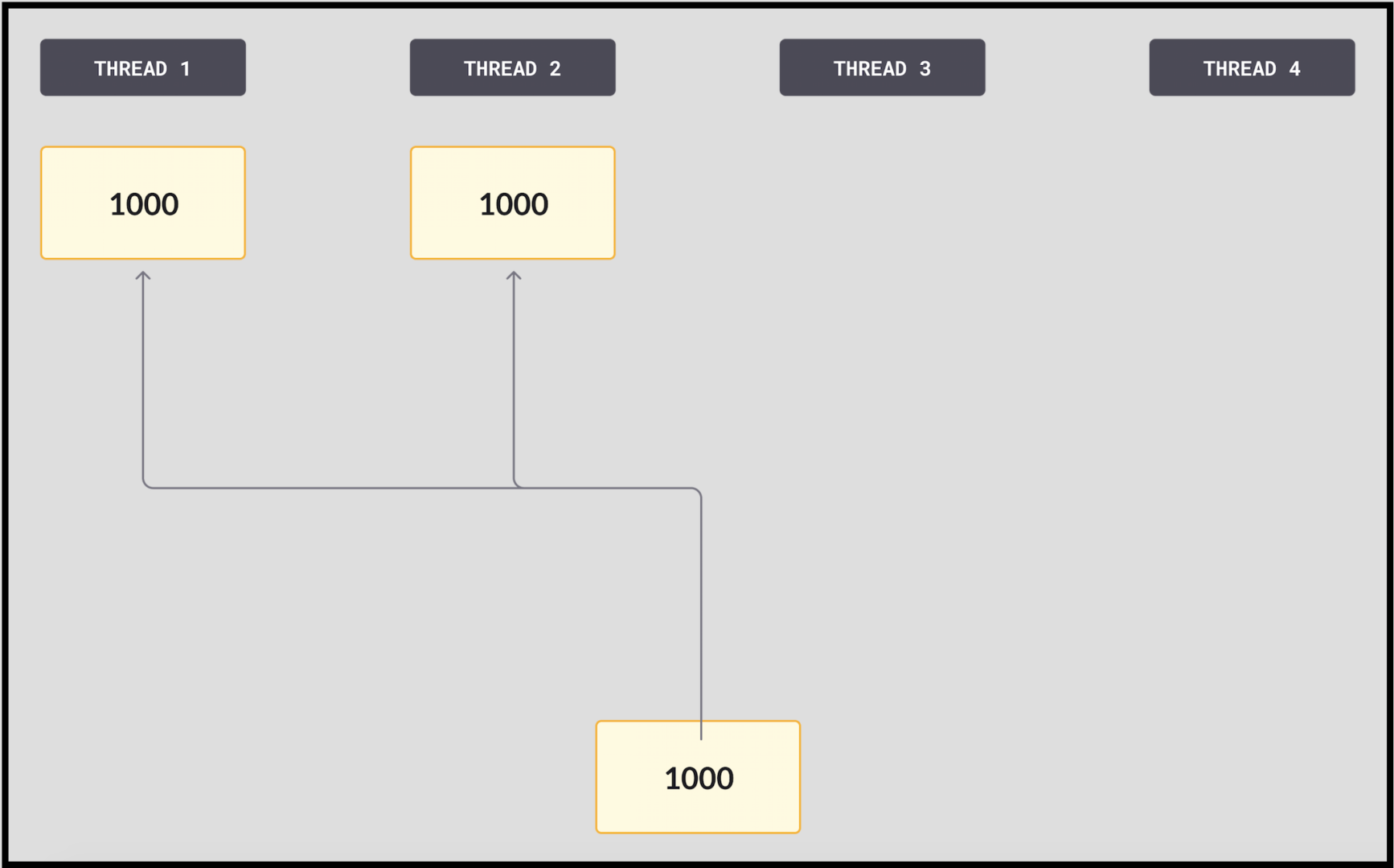
2. 각 스레드는 커밋하려는 작업에 필요한 페이지 수를 예약합니다. 이 경우 스레드1은 페이지의 일부만 예약하므로 가장 최근의 LSN을 1001로 변경하고, 스레드2는 많은 수의 페이지를 예약하고 있으며, 2000으로 변경하려고 합니다. 두 스레드는 동시에 비교-교환(CAS)을 시도합니다. 이 예에서 스레드2가 먼저 도착하여 LSN이 1000이 될 것으로 가정합니다. 스왑을 수행하고 커밋된 LSN인 앵커를 2000으로 대체합니다. 이 광범위한 페이지를 소유하고 오랫동안 바쁘게 작업할 수 있습니다.
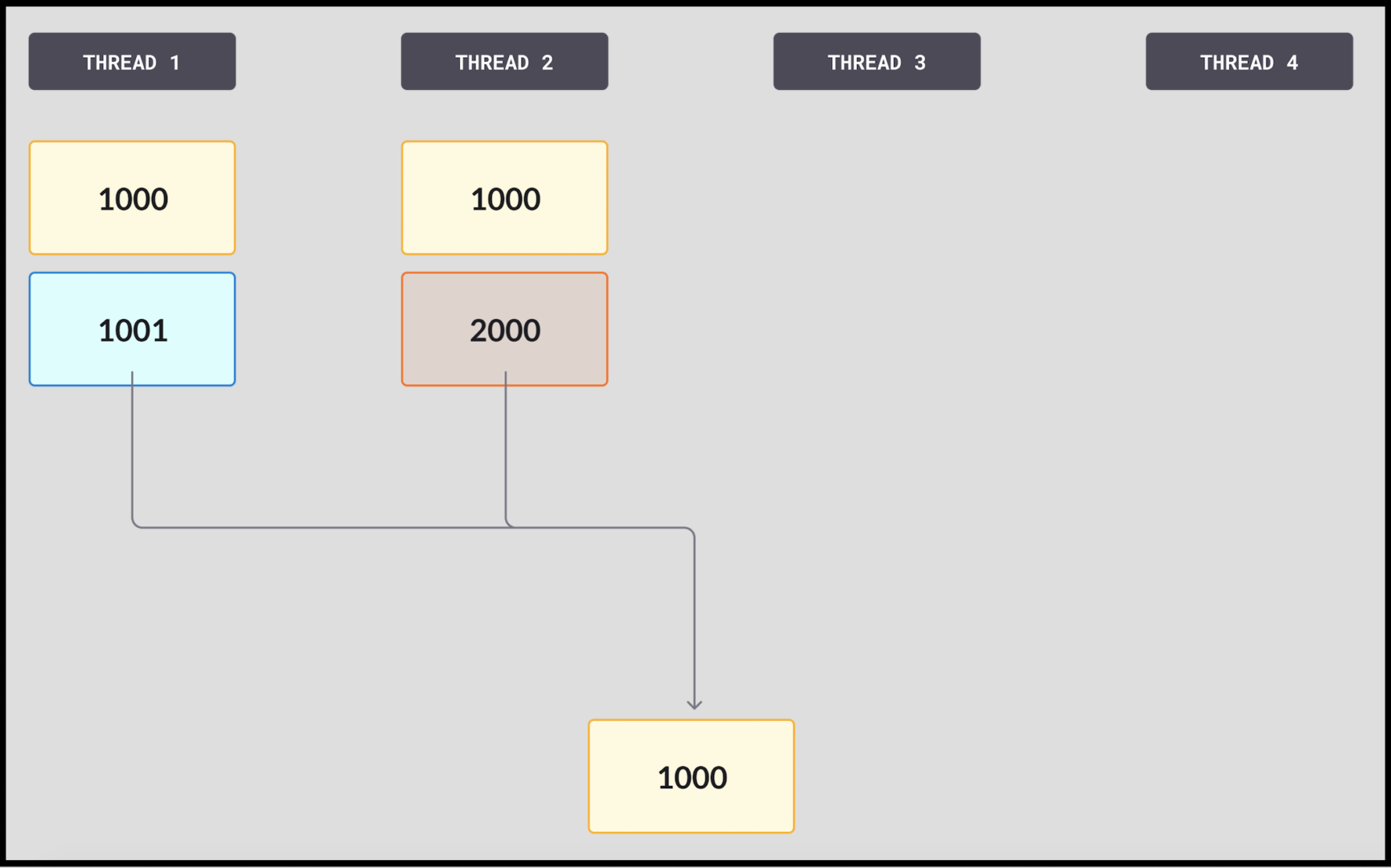
3. 스레드1은 앵커가 1000일 것으로 예상되는 앵커를 읽습니다. 다른 숫자인 2000을 보면 비교에 실패합니다.
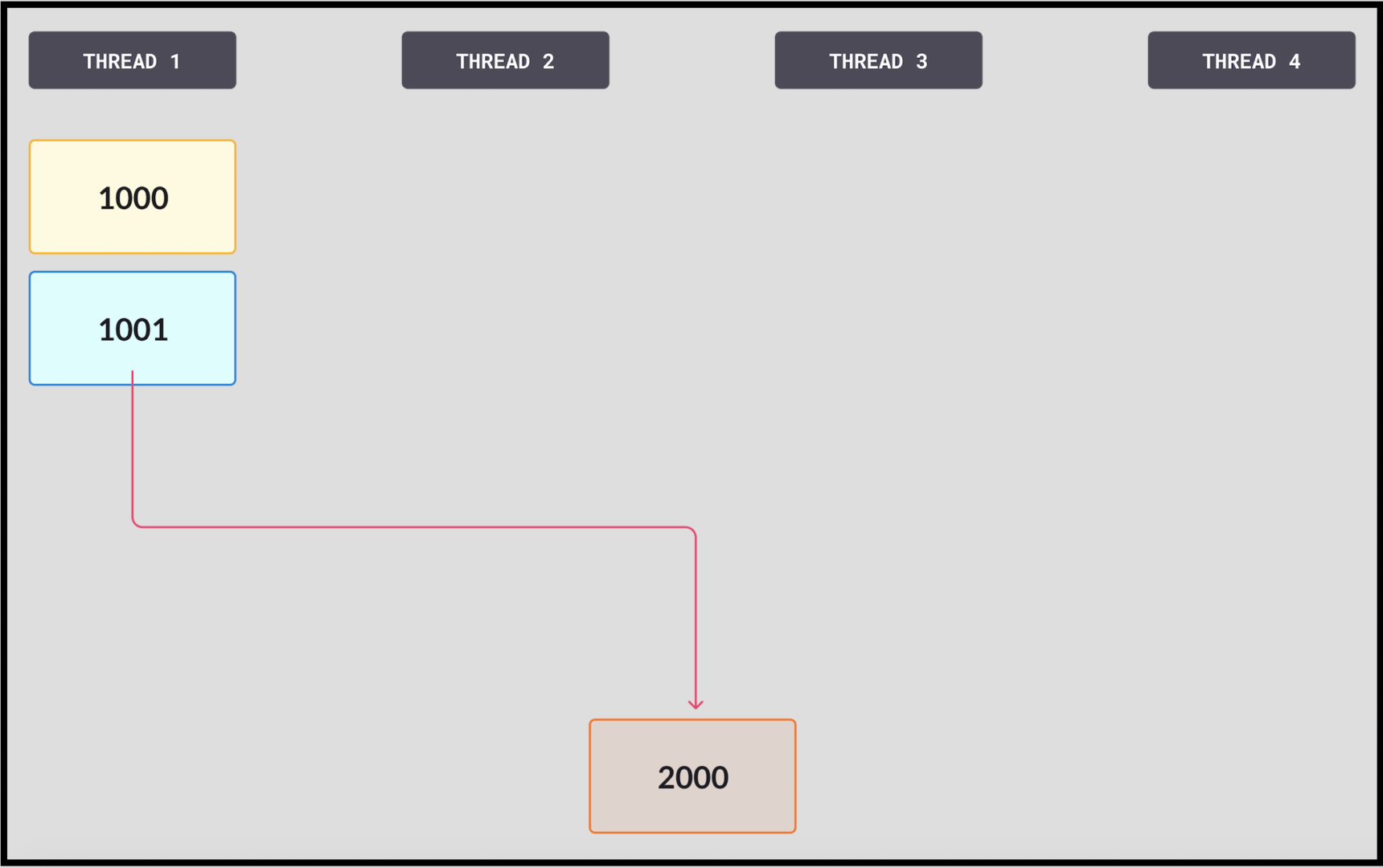
4. 스레드1은 다시 2000의 새로운 값을 메모리에 로드하여 다시 시도합니다. 그런 다음 성공합니다.

CAS 작업이 빠르다는 점에 유의해야 합니다. 스레드가 성공하면 페이지를 구성하고, 로그를 메모리에 쓰고 전송하기 위해 많은 양의 작업이 시작됩니다. CAS 작업은 훨씬 빠릅니다. 또한 실패하면 다른 스레드의 CAS 작업이 성공했기 때문입니다. 항상 작업이 완료되고 있습니다. 스레드나 시스템 전체에 대해 성능 저하 없이 스레드가 여러 번 실패할 수 있습니다.
반대로 SingleStore가 사용했던 이전 방법에서는 LSN 값 주위에 큰 뮤텍스(잠금)가 있는 것처럼 나타났습니다. 모든 스레드는 액세스 권한을 얻고 페이지를 병렬로 작성하는 대신 대기해야 했습니다. 새로운 방법에 비해 오래된 방법은 매우 느렸습니다.
장애 조치에서 마스터 데이터 저장소가 실패하고 슬레이브가 마스터로 승격됩니다. 새로운 마스터는 이제 받은 모든 업데이트를 재생합니다.
이전 마스터는 기본 서버가 실패한 지점이기 때문에 슬레이브로 전달되지 않은 페이지를 수신했을 수 있습니다. 그러나 동기식 복제에서는 아무런 문제가 없습니다. 마스터에게만 제공되는 페이지는 사용자에게 확인되지 않았습니다. 그런 다음 사용자는 다시 시도하고 새 기본 서버는 업데이트를 수행하여 새 슬레이브로 보내고 성공적인 수신 확인을 받고 업데이트가 성공했음을 사용자에게 확인합니다.
성능에 미치는 영향
가장 좋은 경우, 트랜잭션마다 사용자에서 마스터로, 마스테에서 슬레이브로, 슬레이브에서 마스터로, 마스터에서 사용자로, 한 번의 왕복이 필요합니다. 이것은 통신 오버헤드가 충분히 낮기 때문에, 작업의 대부분을 차지하는 다른 처리에서 상각됩니다.
위에서 언급했듯이 동기식 복제를 설정하는 비용은 동시성이 높은 OLTP 벤치마크인 TPC-C의 결과에 한 자릿수%(백분율)의 영향만 미칩니다. 따라서 대부분의 사용자에게 훨씬 더 나은 데이터 일관성 스토리를 효과적으로 추가할 수 있게 합니다.
위의 단계는 주요 내용만을 보여 주지만, 새로운 동기식 복제가 제대로 작동하도록 하는 다른 흥미로운 부분들이 많이 있습니다. 이러한 기능에는 비동기 복제, 다중 복제, 더 높은 수준의 HA를 위한 체인 복제, 블로그 복제, Blob에 대한 가비지 콜렉션, 순산 감지, 우리가 언급 한 내구성이 포함됩니다. 이러한 모든 새로운 기능이 결합되어 동기식 복제 기능이 미치는 영향을 최소화하고, 사용자와 시스템 모두에게 공유 목표를 달성할 수 있는 여러 가지 방법을 제공합니다.
결론
SingleStore의 매우 빠른 성능에 영향을 주지 않는 동기식 복제는 SingleStore와 함께 사용하기 위해 SoR (System of Record) 기능을 필요로 하는 많은 새로운 사용 사례를 있게 합니다. 또한 SingleStore DB 7.0의 새로운 증분 백업 기능은 SoR 워크로드를 추가로 지원합니다.
여기서는 메모리에 유지되는 SingleStore의 로우스토어(Rowstore) 테이블을 사용하여 수행한다고 가정합니다. 로우스토어 테이블과 컬럼스토어(Columnstore) 테이블은 다양한 종류의 빠른 분석을 지원합니다.
따라서 SingleStore 데이터베이스 소프트웨어는 여러 테이블과 다른 테이블 유형의 조인 및 유사한 작업을 포함하여 트랜잭션과 분석을 결합하는 더 많은 하이브리드 사용 사례에 사용될 수 있습니다.
이러한 하이브리드 사용 사례는 SingleStore Universal Storage와 같은 이 릴리스의 다른 SingleStore 기능으로 부터 특정 이점을 얻을 수 있습니다. 현재 고객은 이미 이러한 새로운 기능을 사용할 가능성을 적극적으로 탐색하고 있습니다.
September 23, 2019
https://www.singlestore.com/blog/replication-system-of-record-memsql-7-0/

Replication at Speed – System of Record Capabilities for SingleStore DB 7.0 - SingleStore Blog - MemSQL is Now SingleStore
MemSQL 7.0, currently in beta, offers fast sync replication and incremental backup. These new capabilities support Tier 1 workloads with system of record transactions.
www.singlestore.com
※ www.a-platform.biz | info@a-platform.biz
'SingleStoreDB > 엔지니어링' 카테고리의 다른 글
| 성능과 확장성을 극대화하기 위한 SingleStore의 Skiplist 인덱스 (0) | 2019.12.27 |
|---|---|
| SingleStore DB 7.0에서 강화된 시계열 데이터 활용 기능 (0) | 2019.12.24 |
| SingleStore_Forum : 컬럼스토어 테이블 최적화, 50GB 이상의 빅테이블 처리를 빅테이블과 작은 테이블로 나누어 처리 (0) | 2019.10.04 |
| 예측분석에 기반한 글로벌 공급망 관리를 위한 SingleStore (0) | 2019.09.03 |
| 중복 광고 타겟팅으로 전환 수 늘리기 (0) | 2019.08.23 |


