


안녕하세요 에이플랫폼 입니다.
저번 싱글 스토리 4화의 내용인 Semantic Search를 SingleStore NoteBooks를 활용하여 직접 따라 해보는 시간을 가져보겠습니다. 싱글 스토리는 아래 링크의 카페에서 확인하실 수 있습니다.
https://cafe.naver.com/aplatformbiz/30178
4화 - 시맨틱 검색(Semantic Search)
안녕하세요, 에이플랫폼의 싱글스토리 시리즈입니다. 최근 생성형 AI 기술이 급격히 발전하면서, 단순한 키워드 기반 검색이 아닌 의미를 이해하는 검색(Semantic Searc...
cafe.naver.com
잠시 들어가기 전에 먼저 간단하게 소개를 드리자면
SingleStore Notebooks는 Jupyter Notebook의 기능을 확장하여 데이터 및 AI 전문가가 쉽게 작업할 수 있게 도와줍니다.
하지만 SingleStore Notebooks 기능을 사용하려면 Singlestore Helios 계정에 가입해야 합니다 .
가입은 무료이며 혜택으로는 Free Starter 티어의 Deployment와 $600의 무료 컴퓨팅 리소스를 추가로 받게 됩니다.
추가적인 자세한 내용은 카페의 SingleStore Free Shared Tier 소개글을 참고해 주세요.
https://cafe.naver.com/aplatformbiz/30147
SingleStore Free Shared Tier 소개
SingleStore Helios cloud 서비스의 새로운 기능인 SingleStore Free Shared Tier 에 대해 알아보겠습니다. SingleStore Heli...
cafe.naver.com
환경 구성
SingleStore홈페이지에서 로그인을 하면 왼쪽의 배너 중 Data Studio를 선택해 줍니다.
스튜디오 에서 New Notebook 클릭 해서 새 SingleStore Notebooks를 생성해 줍니다.
원하시는 이름을 입력 후 생성 하면

위의 사진과 같은 화면이 나오면 실습 준비는 끝났습니다.
이제 본격적으로 실습을 진행해 보겠습니다.
실습
1. 필요한 라이브러리 설치
먼저 sentence-transformers 라이브러리를 설치해야 합니다.
Jupyter Notebook 셀에서 아래의 코드를 실행합니다.
!pip install sentence-transformers
2. 라이브러리 가져오기
from sentence_transformers import SentenceTransformer, util
import numpy as np3. 사전 학습된 모델 로드
sentence-transformers 라이브러리에서 미리 훈련된 모델을 사용합니다.
사용하는 모델은 의미론적 유사성 작업에 유용한 임베딩을 생성하도록 학습되었습니다.
model = SentenceTransformer('all-MiniLM-L6-v2')4. 문서 및 쿼리 정의
일부 문서와 쿼리를 정의합니다.
문서는 문장, 단락 또는 더 긴 텍스트 블록일 수 있습니다.
# Example documents
documents = [
"The quick brown fox jumps over the lazy dog.",
"I had a great time at the park with my friends.",
"The economy is showing signs of recovery after the pandemic.",
"The surface of Mars is red due to iron oxide.",
"Machine learning models have become very sophisticated."
]
# Example query
query = "Natural language processing models"5. 문서와 쿼리 인코딩
# Encode the documents
document_embeddings = model.encode(documents)
# Encode the query
query_embedding = model.encode(query)6. 시맨틱 검색 수행
코사인 유사성을 사용하여 쿼리와 의미상 가장 유사한 문서를 찾습니다.
# Compute similarity scores of the query against all document embeddings
similarity_scores = util.pytorch_cos_sim(
query_embedding,
document_embeddings
)
# Find the index of the highest score
highest_score_index = np.argmax(similarity_scores)
print("The most semantically similar document to the query:")
print(documents[highest_score_index])출력은 "자연어 처리 모델"이라는 쿼리와 함께 코사인 유사성 점수가 가장 높은 미리 정의된 목록의 문서가 됩니다.
이 점수는 sentence-transformers 모델에 의해 생성된 임베딩 공간의 컨텍스트에서 문서가 쿼리와 얼마나 유사한지를 나타내는 수치 표현입니다.

출력 결과는 위의 사진과 같습니다.
이 예제에서 모델은 기계 학습 모델을 말하는 문서가 자연어 처리 모델에 대한 쿼리와 의미상 가장 유사하다고 결정했습니다.
이는 쿼리의 정확한 단어가 문서에 없을 수도 있지만 두 문장 모두 AI 분야와 모델 및 학습의 기본 개념과 관련이 있기 때문입니다.
출력을 향상시켜 더 많은 정보를 제공하거나 필요에 따라 다르게 형식을 지정할 수 있습니다.
다음은 몇 가지 선택 사항입니다.
DataFrame 디스플레이
테이블 형식을 선호하는 경우 pandas를 사용하여 문서와 유사성 점수를 표시하는 DataFrame을 만들 수 있습니다.
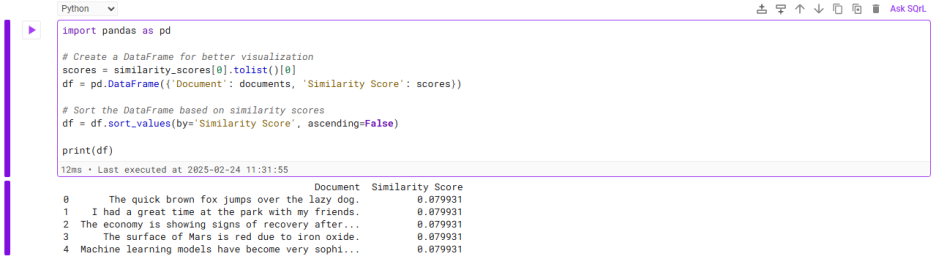
유사성 점수 시각화
막대 차트를 만들어 각 문서의 유사성 점수를 시각화할 수 있습니다.
# 모듈 에러시 matplotlib 설치
!pip install matplotlib
import matplotlib.pyplot as plt
# Plot the similarity scores
plt.bar(range(len(documents)), similarity_scores[0].tolist()[0])
plt.xticks(range(len(documents)), range(1, len(documents)+1))
plt.xlabel('Document Number')
plt.ylabel('Similarity Score')
plt.title('Semantic Similarity Scores')
plt.show()
개념을 이해하기 위해 이 SingleStore Notebook 으로 할 수 있는 일이 훨씬 더 많습니다.
SingleStore Spaces에서 사용 가능한 모든 자습서를 확인해보세요.
시맨틱 검색 엔진으로서의 SingleStore
현대의 검색 기술은 단순한 키워드 일치 방식을 넘어, 의미를 이해하고 컨텍스트를 반영하는 시맨틱 검색(Semantic Search)로 진화하고 있습니다.
SingleStore는 고차원 벡터 데이터를 저장하고 효율적으로 쿼리할 수 있는 기능을 제공하여, 강력한 시맨틱 검색 플랫폼을 구축할 수 있도록 지원합니다.
SingleStore에서는 벡터 임베딩(Vector Embeddings)을 바이너리(Binary) 또는 BLOB 열에 직접 저장할 수 있습니다.
또한, 내장된 벡터 연산 함수들을 활용하여 효율적인 유사성 검색이 가능합니다.
예를 들어, dot_product 함수를 사용하면 벡터 간의 유사도를 빠르게 계산하여 검색 결과의 정확도를 높일 수 있습니다.
SingleStore는 Universal Storage라는 특허 기술을 통해 OLTP 및 OLAP 워크로드를 모두 최적화합니다. 이를 기반으로 빠른 트랜잭션과 실시간 분석을 동시에 수행할 수 있으며, 대규모 벡터 검색 환경에서도 뛰어난 성능을 제공합니다.
특히,
✔ 분산 아키텍처(Distributed Architecture): 대량의 벡터 데이터를 저장하고 확장 가능한 검색을 지원
✔ 병렬 처리(Parallelization): 여러 노드에서 벡터 연산을 병렬로 실행하여 속도 향상
✔ Intel SIMD 기반 벡터 연산: 하드웨어 최적화를 활용하여 벡터 유사성 검색을 가속화
이러한 기술적 이점 덕분에, SingleStore는 대량의 데이터를 빠르게 처리하고 실시간 시맨틱 검색을 가능하게 합니다.
SingleStore를 활용하면 애플리케이션이 사용자의 검색 의도와 맥락을 이해하여 보다 정교한 검색 결과를 제공할 수 있습니다.
또한, 에이플랫폼은 국내 기업들이 시맨틱 검색을 포함한 최신 데이터 기술을 손쉽게 활용할 수 있도록 지원하고 있습니다.
검색 속도와 정확도를 동시에 보장하는 SingleStore의 벡터 검색 기능과 에이플랫폼의 전문적인 기술 지원을 통해, 보다 혁신적인 검색 경험을 만들어 보세요!
이번 시간에는 Semantic Search 예제를 함께 살펴보았습니다.
SingleStore를 활용한 시맨틱 검색이 어떻게 동작하는지 직접 경험해보는 좋은 기회가 되었기를 바랍니다.
더 많은 정보와 실전 활용 팁이 궁금하다면 네이버 카페에서 확인해 보세요!
카페에서는 SingleStore 사용자들과의 소통뿐만 아니라, 다양한 이벤트와 실제 사용 사례 공유도 진행되고 있습니다.
👉 네이버 카페 가입하고 함께 이야기 나눠보세요!





다음 시간에도 유익한 정보와 흥미로운 이야기로 찾아뵙겠습니다! 😊
'SingleStoreDB > 엔지니어링' 카테고리의 다른 글
| SingleStore로 구현한 실시간 자동완성과 오타 허용 (0) | 2025.03.14 |
|---|---|
| DashApp 따라하기 with SingleStore (0) | 2025.02.27 |
| SingleStore 클러스터 구축 (0) | 2025.02.04 |
| 카프카(kafka) 싱글 노드 클러스터 구축 (0) | 2025.02.03 |
| SingleStore : HTAP - Local Storage Database Demo (0) | 2022.10.18 |



