
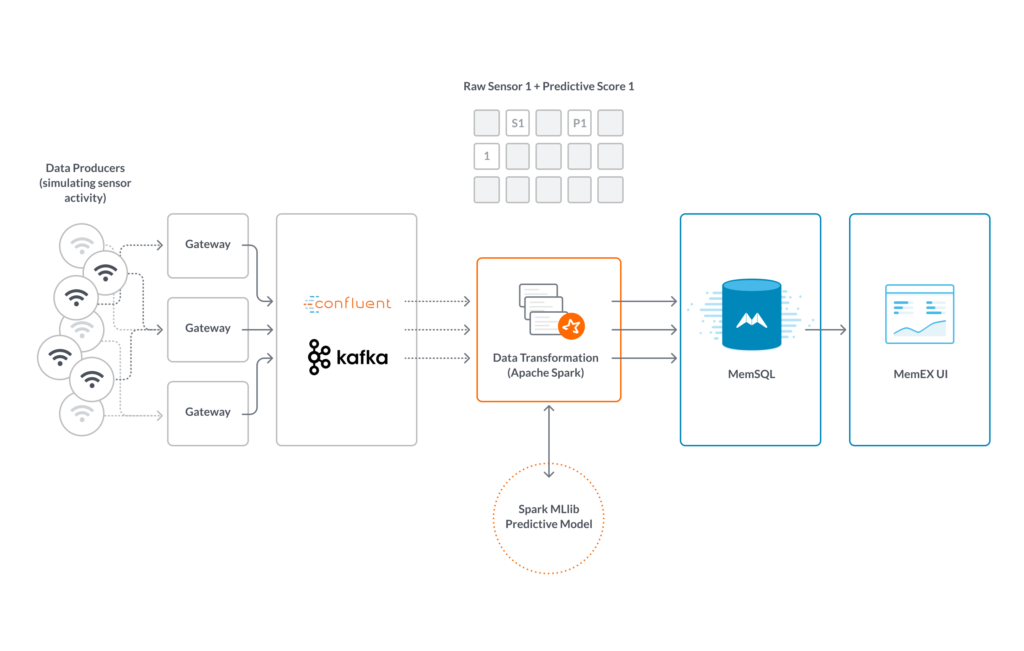
정확히 한 번 시맨틱(exactly-once semantics)을 가진 운영 유연성(operational flexibility)을 위해 Kafka, Spark, SingleStore Pipeline 및 Stored procedures를 사용하십시오.
Spark Connector
SingleStore(MemSQL) Spark Connector는 Apache Spark 2.0 및 2.1과 통합되며 데이터베이스 테이블 및 Spark DataFrames에서 데이터로드 및 추출을 지원합니다.
GitHub 저장소 에서 Spark Connector를 다운로드 할 수 있습니다. Spark Connector에 대한 스칼라 참조 문서는 하단의 링크를 통해 볼 수 있습니다. (https://docs.singlestore.com/v7.1/third-party-integrations/spark-3-connector/)
이 항목에서는 Spark Connector 2.0을 구성하고 시작하는 방법에 대해 설명합니다.
Prerequisites
SingleStore 6.0 이상을 사용하는 경우 Spark Connector 2.0.5 이상을 사용해야합니다. 또한 Spark Connector 2.0 라이브러리에는 Apache Spark 2.0 이상이 필요하며 기본적으로 Spark 버전 2.0.2에 대해 테스트되었습니다.
Installation
프로젝트 정의 내에서 sbt 또는 Maven을 사용하여 SingleStore Connector에 대한 종속성을 추가하십시오.
sbt Configuration:
libraryDependencies += "com.memsql" %% "memsql-connector" % "2.0.2"Maven Configuration:
<dependency>
<groupId>com.memsql</groupId>
<artifactId>memsql-connector_2.11</artifactId>
<version>2.0.2</version>
</dependency>
Configuration Settings
SingleStore Spark Connector는 Spark SQL의 데이터 소스 API를 활용합니다. SingleStore에 접속은 다음의 Spark 설정에 의존합니다.
|
Setting Name |
Default Value |
|
spark.memsql.host |
localhost |
|
spark.memsql.port |
3306 |
|
spark.memsql.user |
root |
|
spark.memsql.password |
None |
|
spark.memsql.defaultDatabase |
None |
|
spark.memsql.defaultSaveMode |
“error” (see description below) |
|
spark.memsql.disablePartitionPushdown |
false |
|
spark.memsql.defaultCreateMode |
DatabaseAndTable |
데이터가 SingleStore 테이블에 로드될 때 defaultCreateMode 커넥터가 데이터베이스 또는 테이블을 만들 지 여부를 지정합니다. 가능한 값은 DatabaseAndTable, Table 및 Skip 값이 아닌 경우 사용자는 해당 작성 권한이 필요합니다.
모든 SingleStore자격 증명은 모든 노드에서 같아야만 쿼리가 직접 종료되는 파티션 푸시 다운을 활용해야합니다.
SingleStore에서 데이터 로딩
다음 예제에서는 illinois 데이터베이스의 customers 테이블에서 DataFrame을 만듭니다. 라이브러리를 사용하려면 Spark가 SingleStore Spark Connector 코드를 호출하도록 매개변수로 전달 하십시오. format.path 옵션은 구문을 사용하여 테이블의 전체 경로입니다. $database_name.$table_name. 테이블 이름만 있는 경우 커넥터는 구성의 기본 데이터베이스 세트에서 테이블을 찾습니다.
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
val conf = new SparkConf()
.setAppName("MemSQL Spark Connector Example")
.set("spark.memsql.host", "10.0.0.190")
.set("spark.memsql.password", "foobar")
.set("spark.memsql.defaultDatabase", "customers")
val spark = SparkSession.builder().config(conf).getOrCreate()
val customersFromIllinois = spark
.read
.format("com.memsql.spark.connector")
.options(Map("path" -> ("customers.illinois")))
.load()
// customersFromIllinois is now a Spark DataFrame which represents the specified MemSQL table
// and can be queried using Spark DataFrame query functions
// count the number of rows
println(s"The number of customers from Illinois is ${customersFromIllinois.count()}")
// print out the DataFrame
customersFromIllinois.show()path옵션 으로 SingleStore 테이블을 지정하는 대신 옵션을 사용하여 SQL 쿼리에서 DataFrame을 만들 수도 있습니다 query. 이 옵션은 SingleStore에서 Spark로 전송되는 데이터의 양을 최소화하고 분산 된 계산을 Spark 대신 SingleStoreL에 푸시 다운합니다. 최상의 성능을 얻으려면 옵션을 사용하여 데이터베이스 이름을 지정 database하거나 기본 데이터베이스가 Spark 구성에 설정되어 있는지 확인하십시오. 이러한 설정을 사용하면 커넥터가 마스터 어그리게이터를 거치지 않고 SingleStore 리프 노드를 직접 쿼리 할 수 있습니다.
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
val conf = new SparkConf()
.setAppName("MemSQL Spark Connector Example")
.set("spark.memsql.host", "10.0.0.190")
.set("spark.memsql.password", "foobar")
val spark = SparkSession.builder().config(conf).getOrCreate()
val customersFromIllinois = spark
.read
.format("com.memsql.spark.connector")
.options(Map("query" -> ("select age_group, count(*) from customers.illinois where number_of_orders > 3 GROUP BY age_group"),
"database" -> "customers"))
.load()
customersFromIllinois.show()
// +-----------+---------+
// | age_group | count(*)|
// +-----------+---------+
// | 13-18 | 128 |
// | 19-25 | 150 |
// | 26+ | 140 |
// +-----------+---------+
SingleStore에 데이터 저장하기
비슷하게 Spark SQL의 Data Sources API를 사용하여 DataFrame을 SingleStore에 저장하십시오. DataFrame을 SingleStorestudents 테이블에 저장하려면:
...
val rdd = sc.parallelize(Array(Row("John Smith", 12), Row("Jane Doe", 13)))
val schema = StructType(Seq(StructField("Name", StringType, false),
StructField("Age", IntegerType, false)))
val df = sqlContext.createDataFrame(rdd, schema)
df
.write
.format("com.memsql.spark.connector")
.mode("error")
.save("people.students")mode는 SingleStoreL 테이블에 기본 키가있는 경우 중복 키를 처리하는 방법을 지정합니다. 지정하지 않으면 기본값(error)이 있습니다 . 즉, 동일한 기본 키가있는 행이 SingleStore의 people.students 테이블 에 이미 있으면 오류가 발생합니다. 다른 저장 모드는 다음과 같습니다.
|
Save Mode String |
Description |
|
“error” |
중복 키가 있는 레코드가 발생하면 SingleStore에서 오류가 발생합니다. |
|
“ignore” |
SingleStore는 중복 키가 있는 레코드를 무시하고 롤백하지 않고 고유 키가 있는 레코드를 계속 삽입합니다. |
|
“overwrite” |
SingleStore는 기존 레코드를 새로운 레코드로 대체합니다. |
SingleStore에 데이터를 저장하는 두 번째 인터페이스는 저장할 DataFrame의 saveToMemSQL 묵시적(implicit) 함수를 통해 이루어집니다.
...
val rdd = sc.parallelize(Array(Row("John Smith", 12), Row("Jane Doe", 13)))
val schema = StructType(Seq(StructField("Name", StringType, false),
StructField("Age", IntegerType, false)))
val df = sqlContext.createDataFrame(rdd, schema)
df.saveToMemSQL("people.students")
// The database name can be omitted if "spark.memsql.defaultDatabase" is set
// in the Spark configuration df.sqlContext.sparkContext.getConf.getAll
Types
Spark에서 SingleStore으로 DataFrame을 저장할 때 각 DataFrame 열의 SparkType은 다음 SingleStore 유형으로 변환됩니다.
|
SparkType |
SingleStore Type |
|
ShortType |
SMALLINT |
|
FloatType |
FLOAT |
|
DoubleType |
DOUBLE |
|
LongType |
BIGINT |
|
IntegerType |
INT |
|
BooleanType |
BOOLEAN |
|
StringType |
TEXT |
|
BinaryType |
BLOB |
|
DecimalType |
DECIMAL |
|
TimeStampType |
TIMESTAMP |
|
DateType |
DATE |
SingleStore 테이블을 Spark DataFrame으로 읽을 때 SingleStore 열 유형은 다음 SparkType으로 변환됩니다.
|
SingleStore Type |
SparkType |
|
TINYINT, SMALLINT |
ShortType |
|
INTEGER |
IntegerType |
|
BIGINT (signed) |
LongType |
|
DOUBLE, NUMERIC |
DoubleType |
|
REAL |
FloatType |
|
DECIMAL |
DecimalType |
|
TIMESTAMP |
TimestampType |
|
DATE |
DateType |
|
TIME |
StringType |
|
CHAR, VARCHAR |
StringType |
|
BIT, BLOG, BINARY |
BinaryType |
SingleStoreL Spark 2.0 커넥터는 Spark 2.0이 현재 사용자 정의 유형을 비활성화했기 때문에 GeoSpatial 또는 JSON SingleStore 유형을 지원하지 않습니다 ( JIRA 문제 참조 ). 이러한 유형은 읽을 때 BinaryType이 됩니다.
참고사이트:
- SingleStore 공식 문서
https://docs.singlestore.com/v7.1/third-party-integrations/spark-3-connector/
Connecting to Spark
Apache Spark is an open-source data processing framework. Spark excels at iterative computation and includes numerous libraries for statistical analysis, graph computations, and machine learning. The SingleStore Spark Connector allows you to connect your S
docs.singlestore.com
- Memsql Spark Connector Github Repository
https://github.com/memsql/memsql-spark-connector
memsql/memsql-spark-connector
A connector for MemSQL and Spark. Contribute to memsql/memsql-spark-connector development by creating an account on GitHub.
github.com
※ www.a-platform.biz | info@a-platform.biz
'SingleStoreDB > 엔지니어링' 카테고리의 다른 글
| 운영 분석(Operational Analytics)의 필요성 (0) | 2019.07.25 |
|---|---|
| SingleStore, Apache Spark 연동 실습 - Count 예제 (0) | 2019.07.25 |
| SingleStore, Apache Kafka 연동 실습 - Quickstart (0) | 2019.07.24 |
| SingleStore, Apache Kafka 연동 개요 (0) | 2019.07.24 |
| SingleStore, Operator for Kubernetes 출시 (0) | 2019.07.24 |



