


안녕하세요, 에이플랫폼의 Support Bulletin 시리즈입니다.
오늘은 타 DB에서 SingleStore로 실시간 데이터를 연동하는 방법을 다뤄보겠습니다.
📌개요
다양한 CDC(Change Data Capture) 솔루션은 Source Connector로 동작하며, 소스 데이터베이스의 변경 사항을 Kafka Topic으로 Publish할 수 있습니다. 이렇게 전달된 변경 정보는 일반적으로 Kafka Sink Connector를 사용해 타겟 데이터베이스에 적용됩니다.

하지만, Kafka Sink Connector는 보통 단일 인스턴스로 동작하기 때문에 운영 시스템에서 병렬로 발생하는 수많은 변경 사항을 SQL을 통해 반영하는 과정에서 성능 저하가 발생할 수 있습니다. 결과적으로 Lag 증가를 피하기 어려워집니다.
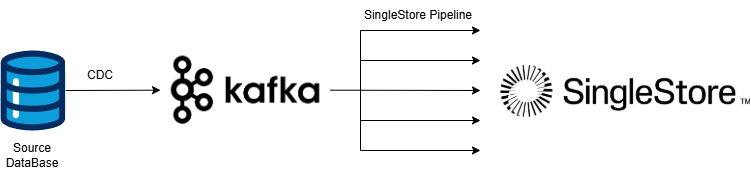
SingleStore의 Kafka Pipeline을 활용하면 Kafka Topic의 메시지를 병렬로 수집(Ingestion)할 수 있으며, 프로시저를 이용해 실시간 변환(Transform)도 가능합니다. 이를 통해 CDC의 Sink Connector 역할을 SingleStore에서 직접 수행하도록 구현할 수 있습니다.
※아래 나올 코드는 샘플 코드 입니다. CDC 의 종류와 버전에 따라 topic의 message 형태가 다양하기에 사용하시는 환경에 맞게 코드를 완성해야 합니다.※
CDC(Change Data Capture) 란?
CDC(Change Data Capture)는 데이터베이스에서 발생하는 삽입(INSERT), 수정(UPDATE), 삭제(DELETE) 등의 변경 사항을 실시간으로 감지하고, 이를 다른 시스템으로 동기화하는 기술입니다.
CDC의 동작 과정은 추출(Extract), 전송(Transport), 적용(Apply) 세 단계로 나눌 수 있습니다.
- 추출(Extract): 소스 데이터베이스에서 변경 사항을 감지하여 수집.
- 전송(Transport): 변경된 데이터를 타겟 시스템으로 전달.
- 적용(Apply): 전달된 데이터를 타겟 시스템에 반영.
오픈소스 CDC 솔루션
Debezium은 현재 가장 인기 있는 오픈소스 CDC 플랫폼 중 하나입니다.
Apache Kafka를 기반으로 구축되었습니다. 세 가지 특징으로는
- 여러 데이터베이스 지원 (MySQL, PostgreSQL, MongoDB etc..)
- 실시간 행 수준 변경 사항 캡처
- Kafka Connect와 통합하여 사용 가능
Maxwell은 MySQL 바이너리 로그를 읽고 행 업데이트를 JSON 형식으로 Kafka로 전달하는 간단한 CDC 도구입니다.
일부 상용 CDC 제품은 고유한 전송 방식을 활용하여 병렬 적용(Parallel Apply) 기능을 제공하기도 합니다.
하지만, 데이터를 Kafka를 통해 전달하는 경우, 적용 단계에서는 일반적으로 Kafka Sink Connector를 사용해야 합니다.
이 때 sink connector는 source connector와 호환되는 connector를 사용해야 합니다.
Source connector의 종류에 따라 추출한 정보를 표기하는 방식이 모두 다르기 때문입니다.
추출과정에서 이전 값(before)와 변경 값(after), 그리고 변경 유형(operation type)을 표기하는 방식이 표준되지 않았습니다.
💡원인
Kafka Sink Connector는 일반적으로 단일 인스턴스로 동작합니다. 따라서 운영 시스템에서 다수의 프로세스에 병렬 발생시키는 대량의 변경 정보를 타겟 시스템에서는 순차적으로(SQL 직렬 처리) 적용해야 하므로, 성능 저하가 발생할 수밖에 없습니다.

위 그림과 같이 Sink Connector가 하나만 실행되면, 동기 지연 (Lag 증가)이 발생해 운영 시스템과 복제 대상 시스템 상이 시점 차이가 커지게 됩니다.
✅동작원리
조금 더 자세히 예를 들어 보겠습니다.
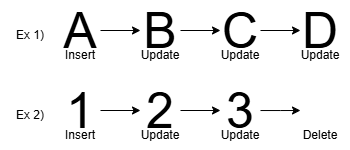
위의 그림에서 예시 1번을 보면, 특정 Row에 값 A가 INSERT된 후, 3번의 UPDATE가 발생했습니다.
이 경우 Kafka Topic에는 변경 사항이 반영된 총 4개의 메시지가 쌓입니다.
그러나 Sink Connector는 순차 실행 방식이므로, 4개의 SQL을 그대로 순차적으로 적용해야 합니다.
하지만 논리적으로 보면, 최종 값 D만 반영하면 되므로 한 번의 INSERT로 처리하는 것이 더 효율적입니다.
예시 2번에서는 특정 Row에 값 1이 INSERT된 후, 2번의 UPDATE 과정을 거친 뒤 DELETE되었습니다.
이 경우에도 Kafka Topic에는 변경 사항이 반영된 총 4개의 메시지가 쌓입니다.
하지만, 논리적으로 보면 최종적으로 Row가 삭제되었기 때문에, 선행하는 3건의 DML(INSERT 및 UPDATE)은 생략하고 DELETE만 수행해도 정합성이 유지됩니다.
결과적으로, 단일 Row에 여러 번의 변경이 발생하더라도 기존 값을 미리 삭제한 후 최종 값만 INSERT하면 정합성을 유지할 수 있습니다.
SingleStore는 Kafka Topic에서 메시지를 Consume한 후, 최종 값을 계산하는 Aggregation 작업과 Target Table 적용을 모두 병렬 처리할 수 있습니다.
이를 통해 단위 시간당 대량의 변경 사항을 효율적으로 반영할 수 있으며, 동기 지연(Lag 증가)을 최소화할 수 있습니다.
Database와 CDC는 변경이 발생하는 컬럼을 로그로 남기고 이를 부분 추출하는 것이 기본 동작입니다.
그렇지만, 이기종 간의 데이터 복제와 지금 설명 드리는 것과 같이 여러 번의 DML 발생을 통합해 한 번에 적용하기 위해서는 추출 단계에서 모든 컬럼의 값을 추출해야 합니다.
이에 대한 설정은 database와 CDC에 따라 다르니 해당 제품의 메뉴얼을 참조하십시오.
👍해결 방법
CDC의 추출과 kafka 전송에 대한 구성이 완료되었다 가정하고 적용을 위한 SingleStore pipeline 관련 코드만을 설명 드리겠습니다.
아래 코드는 mongodb source connector 를 예시로 작성되었습니다.
topic payload의 format은 json입니다.
※아래의 코드는 샘플 코드 입니다. CDC 의 종류와 버전에 따라 topic의 message 형태가 다양하기에 사용하시는 환경에 맞게 코드를 완성해야 합니다.※
-- Target 테이블 생성
create table target_table (
_id as doc::$_id persisted text,
col_1 as JSON_EXTRACT_BIGINT(doc, 'col_1') persisted bigint,
col_2 as JSON_EXTRACT_BIGINT(doc, 'col_2') persisted bigint,
doc json,
primary key (col_1, col_2),
key (_id),
sort key (col_1),
shard key (col_1)
);
-- 프로시저 생성
DELIMITER //
-- SingleStore는 kafka topic에서 수신된 또는 허용 최대치의 message를 가져와 procedure에 전달합니다.
create or replace procedure target_table ( batch query(payload json ) ) as
begin
-- payload를 통해 전달된 변경 내역 집합을 건별 적용하면 sink connector의 적용 속도와 비교해 장점이 없게됩니다.
-- 아래와 같이 payload를 target table에 일괄 적용합니다.
-- MongoDB Connector의 경우 after 값에 해당하는 full document를 제공합니다.
-- 변경이 발생한 document를 document ID 를 이용해 삭제 처리합니다.
delete from target_table where _id in (select distinct payload::documentKey::$_id from batch);
-- chunk migration 또는 document 삭제 후 재생성 등 특별한 경우를 대비해,
-- 논리적인 primary key 기반으로 추가 삭제합니다.
delete m from target_table as m join batch as b
where m.col_1 = JSON_EXTRACT_BIGINT(b.payload::fullDocument, 'col_1')
and m.col_2 = JSON_EXTRACT_BIGINT(b.payload::fullDocument, 'col_2')
and b.payload::$operationType in ('insert', 'update');
-- 이전 문장에서 미리 삭제했기에 단순히 insert해도 됩니다.
-- 그렇지만 추출과 적용 과정에 예외적으로 발생할 수 있는 상황을 대비해 upsert를 사용했습니다.
replace into target_table (doc)
select doc
from (select payload::$operationType as opcode,
payload::fullDocument as doc,
-- 특정 Row의 마지막 변경을 찾기 위해 정렬합니다.
row_number() over (partition by payload::documentKey::$_id order by payload::clusterTime::$timestamp::t desc) as rn
from batch
where (payload::$operationType in ('insert', 'update') and payload::fullDocument <> 'null')
or (payload::$operationType in ('delete'))
)
where rn = 1 and opcode in ('insert', 'update');
end //
DELIMITER ;
--파이프라인 생성
-- 최대 성능을 이해 SingleStore의 partition 과 Kafka topic의 partition을 같게 설정하길 권장합니다.
create or replace pipeline target_table_pipe
as load data kafka '{kafka-host}:9092/{source-table}'
batch_interval {500}
max_partitions_per_batch {4}
skip parser errors
into procedure target_table
format json
(
payload <- %
);
이번 포스팅에서는 SingleStore의 Pipeline 기능을 활용하여 Kafka 기반의 CDC 환경에서 속도가 느린 Sink connector를 대체하는 방법을 살펴보았습니다.
이처럼 SingleStore pipeline은 대량 데이터 또는 스트림 데이터의 고속 적재 뿐 아니라 데이터 리플리케이션에도 활용할 수 있습니다.
SingleStore는 대규모 데이터를 실시간으로 처리하는 데 최적화된 분산형 데이터베이스이며, MySQL과의 높은 호환성을 제공합니다.
이러한 특성 덕분에 기존 MySQL 기반 애플리케이션을 원활하게 마이그레이션하고 통합할 수 있습니다.
에이플랫폼과 함께 SingleStore를 도입하면, MySQL의 익숙한 개발 환경을 유지하면서도 고성능 분산 데이터베이스의 이점을 극대화할 수 있습니다. 이를 통해 데이터 처리 속도를 획기적으로 향상시키고, 비즈니스 성과를 극대화할 수 있습니다.





'SingleStoreDB > Support Bulletin' 카테고리의 다른 글
| [Support Bulletin 06] - Division by Zero (0) | 2025.03.07 |
|---|---|
| [Support Bulletin 05] - Red Hat 9.2 Memory 할당 에러 (0) | 2025.02.19 |
| [Support Bulletin 03] - Kafka Pipeline 의 zstd 압축 포맷 지원 (0) | 2025.02.04 |
| [Support Bulletin 02] - SingleStore JDBC 및 rewriteBatchedStatements 옵션 사용 시 Parameter Capacity 초과 에러 (0) | 2025.01.16 |
| [Support Bulletin 01] - SingleStore Service Autostart 실패 (0) | 2025.01.13 |



